Intégrer une API tierce non stabilisée : quelle solution ?
4 mai 2023
lephare
Comment poursuivre le développement d’un projet qui dépend d’une API non stabilisée ? Retour d’expérience de Pierre, développeur au Phare.
Le contexte
“Bonjour. Il y a un problème. Pour avancer sur votre projet, nous avons besoin d’utiliser votre API. Hier, elle fonctionnait correctement. Aujourd’hui ce n’est plus le cas. Pour que nos développeurs puissent continuer sans perdre de temps, comment faire ?”
Comment poursuivre le développement d’un projet qui dépend d’une API non stabilisée ?
Il y a quelques mois, j’ai trouvé une réponse en lisant le post intitulé “Efficiently Mock APIs Locally With Prism” écrit par Mathieu Santostefano de JoliCode.
Prism permet de lancer un serveur d’API avec des bouchons générés via faker, qu’il déduit à partir de l’OpenAPI Spec.
En consultant la doc de l’outil Prism, j’ai appris qu’il existait, en plus du mode “mock”, un mode “proxy”.
Si l’API est en erreur, le serveur Prism renvoie le bouchon avec le mode proxy plutôt que l’erreur.
Si l’API fonctionne, on obtient bien entendu la réponse de celle-ci. Avoir une réponse de l’API est toujours plus pertinent qu’un bouchon conçu à partir de faker ou d’un exemple, obsolète par définition.
Pour plus de détails, lisez le decision diagram.
La problématique
Voici concrètement le contexte qui nous a conduit à utiliser Prism en mode proxy :
Cela fait 4 mois que notre équipe développe le projet “Transhumance” (nom factice de projet) pour le compte du client “Foobar” (nom factice)
Nous devons livrer le projet “Transhumance” dans 1 mois. Mais ce projet repose en grande partie sur une API liée à des règles métiers spécifiques. Pour illustrer ce propos et cet exemple, nous l’appellerons “élevage”. Elle est développée par une autre équipe de devs que nous appellerons “bergers”.
Nous pouvons consommer cette API… mais elle est instable :
L’API “élevage” devait être livrée il y a 1 mois, mais pour diverses raisons celle-ci est toujours en cours de développement (par notre client Foobar)
Pour une même requête, selon les modifs poussées par l’équipe “bergers” nous faisons face à quelques régressions (HTTP 500) qui nous ralentissent dans l’intégration de l’API dans le projet (temps de debug, temps de context switching…)
L’API “élevage” a pris du retard, mais la livraison du projet ne peut être retardée. Alors comment faire ?
La solution
Heureusement, l’équipe “bergers” qui a conçu en amont l’API “élevage” a mis à disposition le contrat via un Swagger (Cf. API First)
Cette approche a sauvé notre intégration, voici pourquoi.
Un Swagger repose sur une OpenAPI specification décrite en JSON.
En inspectant le code source de la documentation, j’ai donc pu obtenir la spec OpenAPI. Code source Swagger

J’ai ensuite converti ce json en yml.
Ainsi, nous pouvons avoir un serveur Prism en mode proxy qui va générer – via faker ou des exemples fournis – des réponses bouchon si et seulement si l’API “élevage” est en erreur.
Sur nos environnements de développement, nous n’interrogeons plus l’APi “élevage” directement (https://elevage.com) mais Prism (http://api_elevage_v1_prism:4011)
Le projet “Transhumance” tournant via un docker-compose sur ma machine, j’ajoute le service suivant :
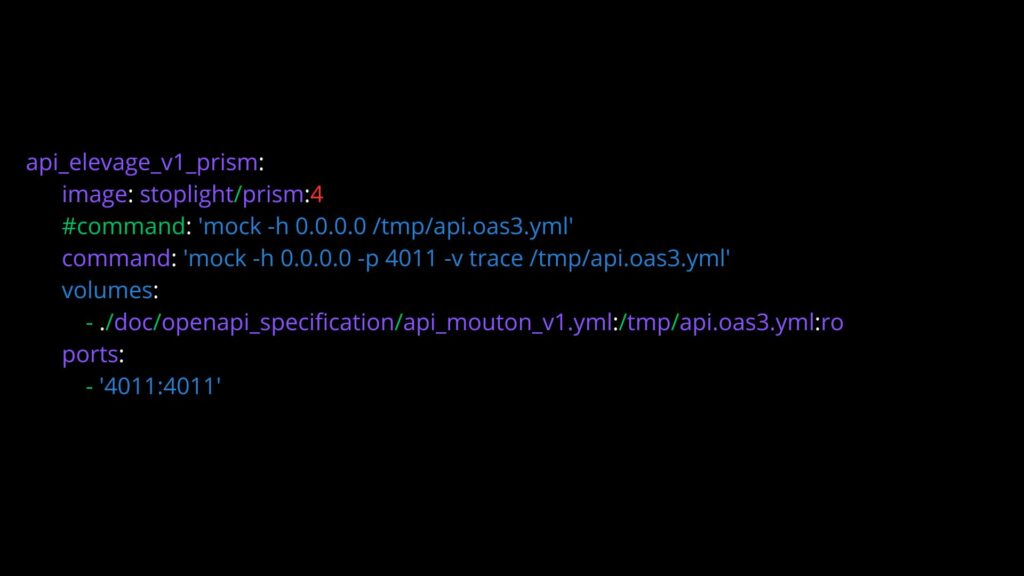
Par exemple, prenons le endpoint “/moutons”. Depuis “Transhumance”, nous avons un configurateur de mouton. Le POST d’un mouton à 4 pattes fonctionne. Dans ce cas, nous préférons avoir la réponse de L’API “élevage”.
En revanche, le POST d’un mouton à 5 pattes ne fonctionne pas encore côté API “élevage”. Dans cet autre cas, nous préférons avoir un bouchon plutôt qu’une 500.
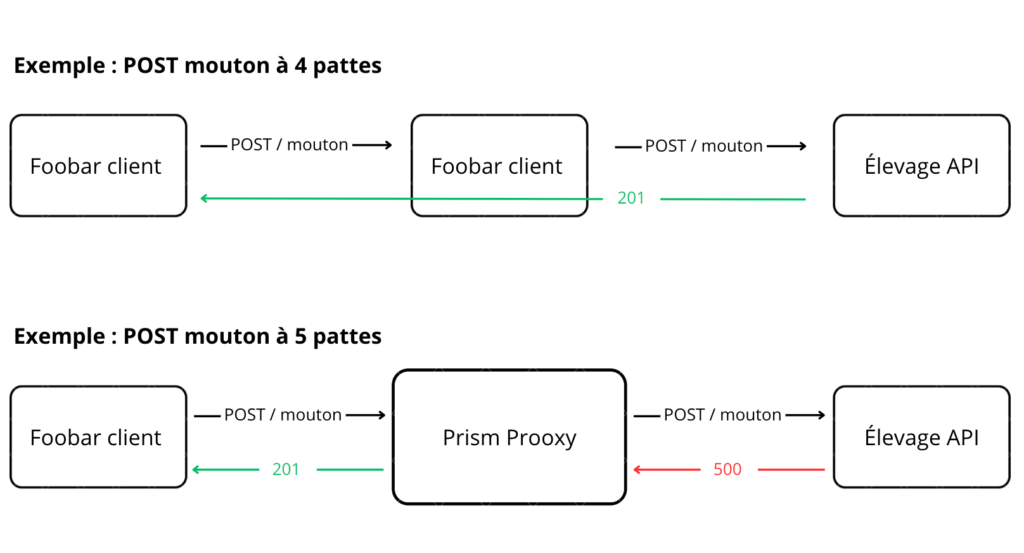
Ainsi, en 30 minutes, notre équipe a acquis une stabilité déterminante pour le bon déroulement du projet “Foobar” et le respect de la roadmap.